Update
I noticed that most people focus on how to conduct strict benchmark testing and how to make the program fun faster. but tha't not my concern . I dont' care which way is faster. What I want to know is whether there are really no extra operations at all after the iterator is optimized by the optimizer. I have some doubts about hte true meaning of zero cost.
Hello everyone. Please look at the following code first:
use std::time::SystemTime;
fn main(){
let v = Box::new(vec![0u8;1_000_000_000]);
let mut v1 = v.clone();
let mut v2 = v.clone();
drop(v);
let start = SystemTime::now();
t1(&mut v1);
println!("t1: {} ms",SystemTime::now().duration_since(start).unwrap().as_millis());
let start = SystemTime::now();
t2(&mut v2);
println!("t2: {} ms",SystemTime::now().duration_since(start).unwrap().as_millis());
}
fn t1(v:&mut Vec<u8>){
let length = v.len();
let mut index = 0usize;
loop {
if index >= length{
break;
}
let element = &mut v[index];
*element += 1;
index += 1;
}
}
fn t2(v:&mut Vec<u8>){
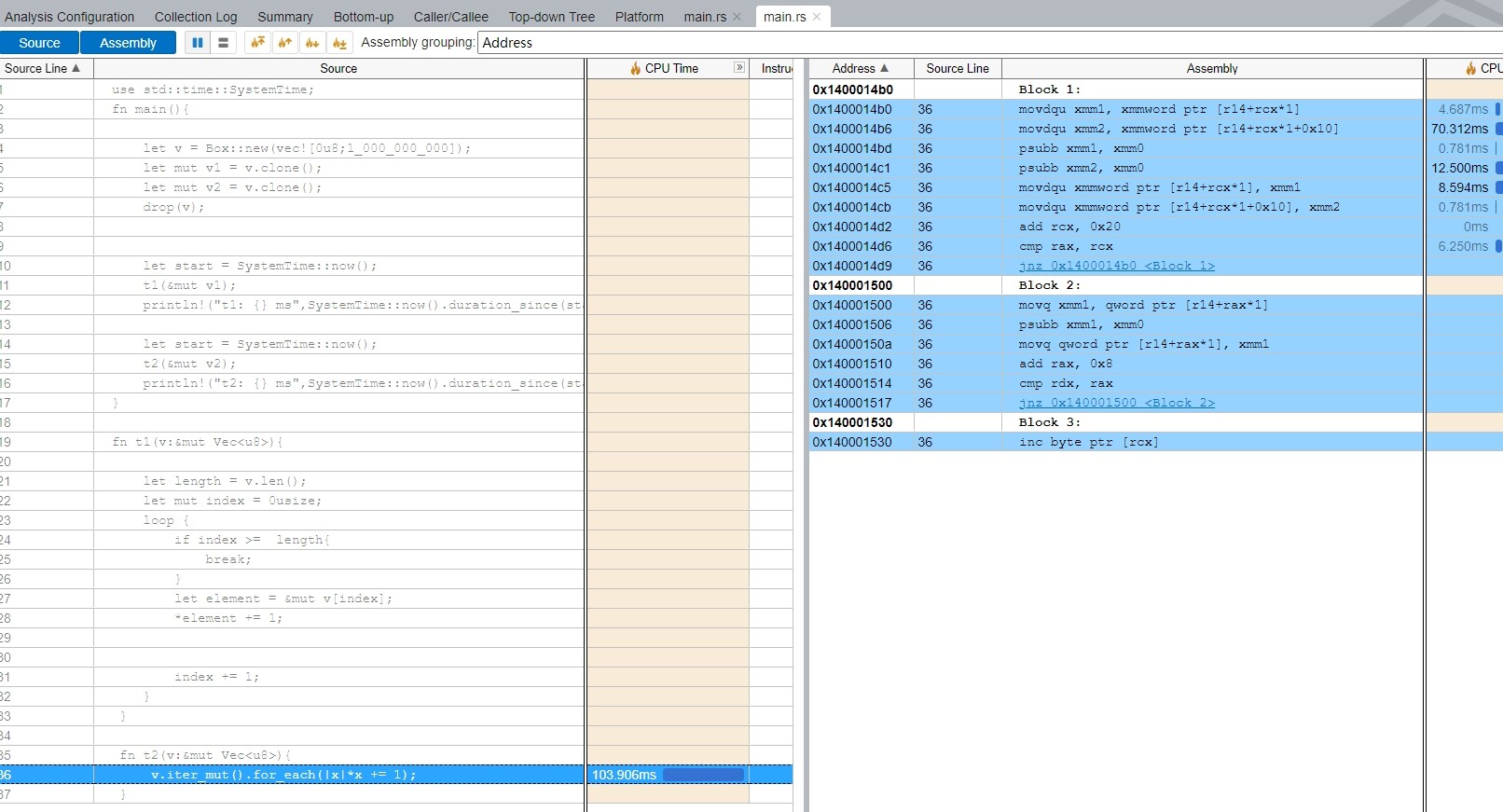
v.iter_mut().for_each(|x|*x += 1);
}
This code will use two methods to +1 values of all elements in Vec to analyze the performance of the two methods.
t1 uses a method similar to for loop in C language, and t2 uses interators and closures to implement.
Running under the Debug binary , t1 is about 1 second faster than t2 for operations of 1 billion elements. when running under release binary, opt_level=3, the perormance gap between t1 and t2 ranges from 1 to 30ms.
Now,I have two questions:
- What additional performance overhead does the use of iterators and closure cause? Although this additional performance overhead is almost negligible, I would like a very detailed answer.
- What more operations does the optimized t2 have than t1? Although I can analyze the performance of the program throught Intel Vtune Profiler, I do not understand some of the advanced assembly instructions of x64.
A friend of mine thinks that using iterators and closures has a huge performance overhead. I know that's not the case, but I can't convince him with the underlying technical principles; So I hope to get a more authoritative and detailed answer.
Thank you all.