Summary
Where clauses occupy a unique position in function signatures and type definitions. They read naturally and clearly, and are easily extensible without hindering habitability. I propose extending where clauses with boolean expressions, enabling a limited subset of formal verification through an SMT solver.
For a minimum representative example, a signature like this:
fn set_flag(&mut self, index: u8) -> Result<(), OutOfBoundsError>;
Could be refactored as:
fn set_flag(&mut self, index: u8) where index < 16;
This new signature would preclude the need for error handling, as all calls to
the function would be statically guaranteed to uphold the invariant on the
index parameter.
Through the proposal, I'll attempt to address the semantics of these extended clauses, possible approaches to deal with the obvious limitations (decidability, compilation time, learning burden) and present an argument for the value of even a minimal implementation of this feature.
Limitations of this Pre-RFC
My background is not on type theory or compilers, but rather in high reliability embedded programming. This means my grasp on the theoretical foundations of what I'm proposing, as well as the details of satisfiability modulo theories, are tenuous at best. I also understand that this proposal is not something new, variations of it have come up with more or less formality from the Rust community, and I don't claim to bring anything ground breaking to the conversation. If anything, I welcome the discussion on this document as a way to learn and broaden my understanding of the problem.
The perspective I'm bringing is mostly concerned with usability, habitability, immediate impact on producing readable and safe code, and mitigation of issues that have come up in past discussions such as compile times, decidability and syntax clarity.
Motivation
To explore the feature, let's use a simplified API to a fixed-frequency pulse-width modulation driver as a motivating example:
pub const NUMBER_OF_PINS: usize = 8;
pub enum PwmError {
PinOutOfRange,
DutyCycleOutOfRange,
PinIsEnabled,
PinIsDisabled,
}
pub struct Pwm;
impl Pwm {
pub fn new(pin: usize) -> Result<Self, PwmError>;
pub fn set_duty_cycle(&mut self, value: u8) -> Result<(), PwmError>;
pub fn enable(&mut self) -> Result<(), PwmError>;
pub fn disable(&mut self) -> Result<(), PwmError>;
pub fn is_enabled(&self) -> bool;
}
While it's simple and it gets the job done, the API above is a bit naive and has a few problems:
- It's unclear at first glance what functions return which error variants. Will
set_duty_cyclework on a disabled pin, as a pre-load of the value prior to the pin being enabled? (This would make sense ifPinIsDisabledis meant to be emitted byfn disable). - What are the limits of the
valueparameter? Domain knowledge tells us it's likely 100, but it's not conveyed by the code. - While the
NUMBER_OF_PINSconstant is pretty obviously meant to limit thepinargument tonew, there's nothing in the interface that enforces this relationship. In more complex modules, the relationship may not be as clear, and would require delving into the source. - It's possible to call functions in invalid states, regardless of our
interpretation of the API (either it's incorrect to call
set_duty_cycleon a disabled pin, or it's incorrect to calldisableon a disabled pin, or both, as we infer from the last variant of the error enum). - All error cases must be handled on all function calls. While Rust offers
powerful tools to simplify this, it's conceptually unnecessary. Additionally when
interfacing with an external library, it's likely that some form of error
conversion will take place, which is a maintenance burden and sometimes
troublesome in
no_stdenvironments. - It's subject to the "mutate-then-fail" bug. A faulty implementation could be:
This kind of bug can take a while to manifest since it lies in the error path, which is normally taken less often.pub fn set_duty_cycle(&mut self, value: u8) { self.inner_write_to_PWM_register(value); if value >= 100 { return Err(PwmError::DutyCycleOutOfRange); } // ... }
In current Rust, there are certainly tools to approach all the problems above. Comments can help clarify which errors to expect where, and parameter ranges. The problem of invalid states can be solved with typestate programming. Mutate-then-fail can be spotted through code review and library inspection. However, these solutions have their own drawbacks. Comments drift out of date. Typestates, though easy in Rust, still carry a syntactic burden and are tough to grasp for beginners. Adding a new error to the enum causes churn as all call sites to the API require an update.
Through this proposal, all of the issues above can be solved with a net improvement in readability:
pub const NUMBER_OF_PINS: usize = 8;
pub struct Pwm;
impl Pwm {
pub fn new(pin: usize) where pin < NUMBER_OF_PINS;
pub fn set_duty_cycle(&mut self, value: u8) where value <= 100 && self.is_enabled();
pub fn enable(&mut self)
pub fn disable(&mut self);
pub fn is_enabled(&self) -> bool;
}
-
The uncertainty about error returns disappears as error handling is eliminated altogether.
-
Valid state transitions are made obvious. With this API, it is clearly valid to call
enableanddisabletwice, whereset_duty_cycleexpects an enabled pin. All valid transitions are enforced without the syntactic burden of typestates. -
The "mutate-then-fail" bug is statically prevented as the function pre-conditions are encoded in the function signature. This means that any execution of the function is guaranteed to occur through the correct path (or panic).
-
The call site is significantly simplified, even in the case of a very basic SMT solver implementation (See "Value of a limited implementation" later). Assuming for the sake of illustration that the SMT solver is capable of verifying all preconditions in this case, a call site like this:
match pwm.set_duty_cycle(some_percent_value) { PwmError::DutyCycleOutOfRange => { log!("Duty cycle out of range."); return Err(MyDomainError::SomeVariant); }, _ => panic!("Unexpected PWM error"), }Would become as simple as this:
pwm.set_duty_cycle(some_percent_value);
I'll later explore the situation where the SMT solver is incapable of guaranteeing the preconditions, and see that the revised API is not only usable, but ergonomic even in the limited case.
Generally, I think it's hard to overstate the readability benefits. Where
clauses have a very natural grammar that maps well to a plain English reading
of the function signature, so their meaning is easy to grasp even for
beginners, arguably more so than the generic Result alternative. Later in this
proposal, I'll make an argument against expanding the feature with more
advanced constructs such as the model keyword for postconditions and
explicit theories, since I believe it's difficult to find a syntax for them
that is as immediately intuitive as the boolean where clause.
Semantics
Boolean expressions containing only calls to pure functions may appear in place of normal trait-bound where clauses. Multiple expressions can be separated by commas (same as trait bound where clauses) or chained by boolean operators. These expressions will be fed to an SMT solver as a final compilation step. Compilation will be aborted if any expression is falsifiable at any point of evaluation.
Each expression would manifest after compilation as a separate progress bar for each point of evaluation (see mockup below). Namely, a line would be printed per each:
- Call to a function with a boolean where clause.
- Construction of a type with a boolean where clause.
- Mutation of a variable when the mutated field is reflected in a boolean where clause.
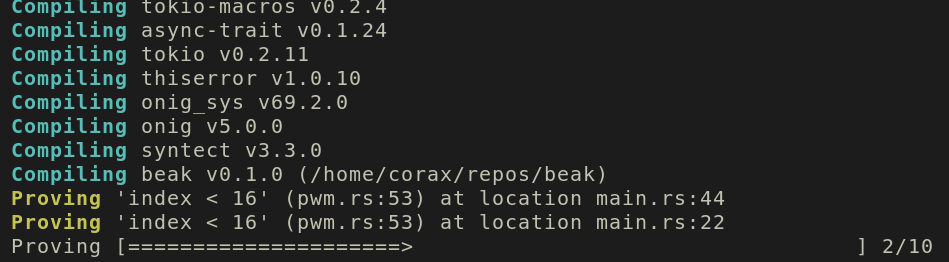
This is a one-to-many correspondence, so a single boolean where clause could result in multiple lines of compiler output. This achieves two goals:
- It provides an intuitive visual for the compilation time spent by the SMT solver.
- It allows the developer to quickly identify the evaluation points that are taking longer to prove, allowing easy insertion of a runtime check (e.g. assert) and highlighting code smells.
Communicating failure correctly is an important aspect of a feature with advanced theoretical grounds. While it would be useful to offer detailed error messages that spell out the specific reason for failure (undecidable for X reason, falsifiable in Y case), as a first approach I propose something like:
Error: could not prove 'index < 16' (pwm.rs:53) at location main.rs:44.
Consider adding a runtime check at main.rs:44, e.g 'assert!(index < 16)'
An error message like this achieves two goals:
- Offers an immediate solution to the compilation error that is universally applicable, even for a very limited SMT solver (adding an assertion with the explicit boolean expression trivializes the proof, without need for any syntactic unification).
- Takes beginners and developers unfamiliar with the feature immediately into
their comfort zone, as the meaning of
assertis widely understood. Theassertcan then be easily refactored away into non-panicking flow control that just branches away if the condition isn't satisfied.
I believe offering this escape hatch is more immediately valuable than offering a detailed explanation why the predicate could not be satisfied, though as the tool evolves, such explanations would likely prove valuable too. In particular, offering this escape hatch would reduce friction with library interfaces; an inexperienced user wouldn't have to worry about incorporating a crate that makes use of boolean where clauses in the API, as there's an easy way to defer the predicates to runtime.
Impact on compilation times
Regardless of the complexity of the SMT solver chosen or developed to implement this feature, compile times would suffer for any application that makes liberal use of it. This could become a big drawback in case boolean where clauses become ubiquitous in library code. I propose two tools to combat this issue:
- An optional compilation flag, named something like
runtime_proofs,assert_at_predicates, or any obvious enough variation. This compilation flag would automatically insert runtime assertions at the evaluation point of every predicate. Enabling it would trivialize all the proofs and eliminate the impact on compilation time. The flag would allow workflows where iteration on the debug build happens with all proofs deferred to runtime, with only nightly or CI builds evaluating them at compile time, without having any impact on the source code. - The combination of the
assertsuggestion error message, with a limited, gradual and conservative SMT solver implementation that only incorporates decidable theories or theories that can be treated in a practical amount of time.
Value of a limited implementation
A common point of discussion in on this topic is how valuable this feature would be, provided that it's built on top of a limited SMT solver. It's an important discussion because no matter how advanced, SMT solvers are inevitably limited, and entire categories of boolean expressions will be undecidable or impractically slow. Therefore, for this feature to be attractive to implement, It would need to guarantee two points:
- It's immediately useful even with a minimal, severely limited SMT solver.
- It can be incrementally expanded without any breakage.
To explore the first point, I propose a thought experiment where this feature is implemented on top of DumbSMT, a comically simple, fictional SMT solver that can only verify predicates at evaluation points that either:
- Are fully evaluable at compile time (constexpr).
- Are preceded by a branch with the exact, explicit predicate expression as a condition.
So, under DumbSMT, the following examples would compile:
let pin = 8;
let pwm = Pwm::new(pin); // Compiles (constexpr)
let pin = runtime_variable;
if !(pin < NUMBER_OF_PINS) { return; }
let pwm = Pwm::new(pin); // Compiles (preceded by branch on explicit predicate)
let pin = runtime_variable;
assert!(pin < NUMBER_OF_PINS);
let pwm = Pwm::new(pin); // Compiles (preceded by branch on explicit predicate)
But these would not:
let pin = runtime_variable;
if !(pin < NUMBER_OF_PINS) { pin = 0; };
let pwm = Pwm::new(pin); // Error! Not branching away
let pin = runtime_variable;
if pin >= 16 { return; };
let pwm = Pwm::new(pin); // Error! Branch condition is not the *exact, explicit* predicate.
A first observation is that, on many codebases, a surprisingly large amount of
conditions will be evaluable at compile time. This is particularly the case for
embedded software, where many of these small-integer bounds trace back to
const definitions of pins, registers, and other compile-time knowledge
extracted from a datasheet. This alone allows cleaning a lot of clutter from
function signatures at no clarity expense at the call site.
For every other situation, the limitations of DumbSMT don't actually incur a habitability cost either. At worst, what used to be error handling:
pub fn foo(pin: u8) -> Result<(), MyError> {
let pwm = Pwm::new(pin).map_err(|_| MyError::DriverError)?;
//...
}
Becomes explicit branching:
fn foo(pin: u8) -> Result<(), MyError> {
if !(pin < NUMBER_OF_PINS) {
return MyError::DriverError;
}
let pwm = Pwm::new(pin);
//...
}
As for runtime cost, it's likely that the bounds check above would've been done as a
first step into Pwm::new(), so there's no loss of performance there either.
While the readability of the two code blocks above will come down to a matter of taste, it's in the same ballpark, and even with these exaggerated restrictions we're already able to opt into the benefits of the Pwm API shown at the start of the proposal. In reality, even a barebones SMT solver would be significantly more capable than DumbSMT, which would remove the need for the stilted flow control. Just being able to handle integer arithmetic and basic syntactic unification would unlock a very expressive range of predicates.
The bottom line is that the boolean where clause is valuable even for predicates that the SMT has no hope to ever prove. Library interfaces with such predicates would be perfectly usable by branching on these conditions or on simple syntactic transformations of them. The only case where a boolean where clause should be rejected at the point of definition (as opposed to evaluation) is when it involves calls to impure functions or any side effects.
Why not go further?
Other languages and frameworks that utilize SMT solvers for verification go further than this proposal. One such language, which I'll use as a reference because its syntax is very similar to Rust's, is ZetZ. In ZetZ, the model and theory keywords are used to explicitly encode function postconditions in the function signature and define type states, respectively.
If we were to apply this approach to Rust, for example through the model keyword, the motivating example API could look like this:
pub const NUMBER_OF_PINS: usize = 8;
pub struct Pwm;
impl Pwm {
pub fn new(pin: usize) where pin < NUMBER_OF_PINS, model self.is_disabled();
pub fn set_duty_cycle(&mut self, value: u8) where value <= 100 && self.is_enabled();
pub fn enable(&mut self) model self.is_enabled();
pub fn disable(&mut self) model !self.is_enabled();
pub fn is_enabled(&self) -> bool;
}
There could be some benefits to an approach like this:
- Clarity of how to achieve the preconditions of functions with precondition predicates. While in the former api we'd have to infer that
is_enabled()is a consequence ofenable(), in this case it becomes explicit. - Additional clarification of type states in ambiguous situations. In the expanded example above, we know that
newproduces a disabled Pwm driver. - Error locality and API stability: Users of a library would be less likely to suffer breakage.
Still, I believe this approach is inadvisable. There are a few reasons why I believe the boolean where clause is all that is needed, and these other keywords should not be pursued.
- It's hard to find a syntactic place for
modelpostconditions andtheorystyle type states that are as intuitive and readable as theirwhereequivalent. Where the meaning of a booleanwhereclause is easy to grasp, a Rust beginner would have a much harder time intepreting whatmodelmeans. - Allowing postconditions to be expressed at the function signature level makes it all too easy to create a disconnect between the function behaviour and the signature, requiring the separate interpretation of each.
- Many of the benefits are already available through typestate programming.
Beyond concrete arguments, I'd say that taking things this far would be an excessive change to Rust, bringing along complex to maintain and explain syntax, while the boolean where clause slots nicely into an existing part of the language.
 have there been previous discussions about why a SMT solver won't be added to the type checker?
have there been previous discussions about why a SMT solver won't be added to the type checker?