This did the trick. So results when running cargo with --release:
existing needle took 982775 nanoseconds and returned true
missing needle took 812924 nanoseconds and returned false
existing needle MEMMEM took 39114 nanoseconds and returned true
missing needle MEMMEM took 38362 nanoseconds and returned false
Testing the exact same needles/haystacks with go:
➤ go build .
➤ ./substring
Finding the needle returned true in 275891 nanoseconds
Searching a missing needle returned false in 70453 nanoseconds
In my case, this convinced me to use memmem to search for substrings if I need performance.
Why not just take the rabinkarp parts from memmem and just add them to the rust core?
Rabin-Karp is mostly a distraction here. At least with respect to memchr::memmem, it is only used to improve latency in certain cases. I don't think it's used at all in your benchmark. The haystack is too big.
The secret sauce for fast substring search is SIMD.
In that case, we can just wait for #68455? Is this ticket still needed? Cause it sounds mostly like this is already Work In Progress and there is a clean and maintained crate which offers a very performant alternative.
You seem to be clinging to the notion that rust core is using a naive search algorithm. It's not. A non-SIMD implementation of Two-Way, which is what's in rust core, should be, on average, in the same performance ballpark as a non-SIMD implementation of Rabin-Karp.
Also keep in mind that by default even debug builds will pull in a optimized release version of the standard library. So if you benchmark something built into std or core then only your benchmark harness is unoptimized which you probably won't notice, whereas if you benchmark a crate without --release then your harness and the code being benchmarked will both have unoptimized codegen.
We've come full circle to what I was saying originally.
I do not think it is a "work in progress" in the sense that someone is actively working on bringing SIMD to core. I would characterize its status as "known issue that folks would love a fix for, but is hard for $reasons both social and technical." (Maybe I'm wrong, but I'm just not aware of anyone actively working on it. If someone else, I'd love to hear about it!)
To drive home my point, a quick profile of your Go program shows absolutely no time spent in Rabin-Karp. Instead, most time is spent in the body of strings.Index too, with indexbytebody a close second. indexbytebody is an AVX accelerated loop that looks for a particular byte. i.e., memchr.
Because in debug mode Rust and LLVM intentionally prefer quick compilation (that generates very naive inefficient code) and completeness and clarity of the code in a debugger (so Rust doesn't omit/simplify anything, even redundant code). The debug mode makes slow programs on purpose — for every trade-off between program's run-time speed and something else it chooses something else.
On top of that Rust is specifically designed to use many layers of abstraction that can be optimized out entirely by the optimizer. Without an optimizer there are many layers of costly abstractions left in the program. It's infeasible to optimize programs for this mode. Even basic constructs like variable assignment and the for loop are abstractions that generate unoptimized code.
I am semi-passively (e.g. not full-time, or even part-time, but I work on it here and there), and was specifically experimenting with the memchr::memmem impl some last week. One major issue with it is that that code is that memchr::memmem assumes the existence of efficient movemsk-style instruction, which doesn't exist on arm/aarch64 (and emulating it is as slow as emulating horizontal ops generally are). Generally algorithms need to be tweaked to avoid it.
I've been meaning to bring this up on memchr::memmem, but wasn't sure where. (Also, sadly, I don't have tons of time to dedicate to this, but it is an area I am interested in)
I would guess it's largely unelided bounds checks that slow the debug build so notably.
A simple example is transposing the bytes in an image, which is just a nested x,y loop assigning bytes from one array to another: at even trivial image sizes (10k) it can take multiple seconds in debug, and microseconds in release.
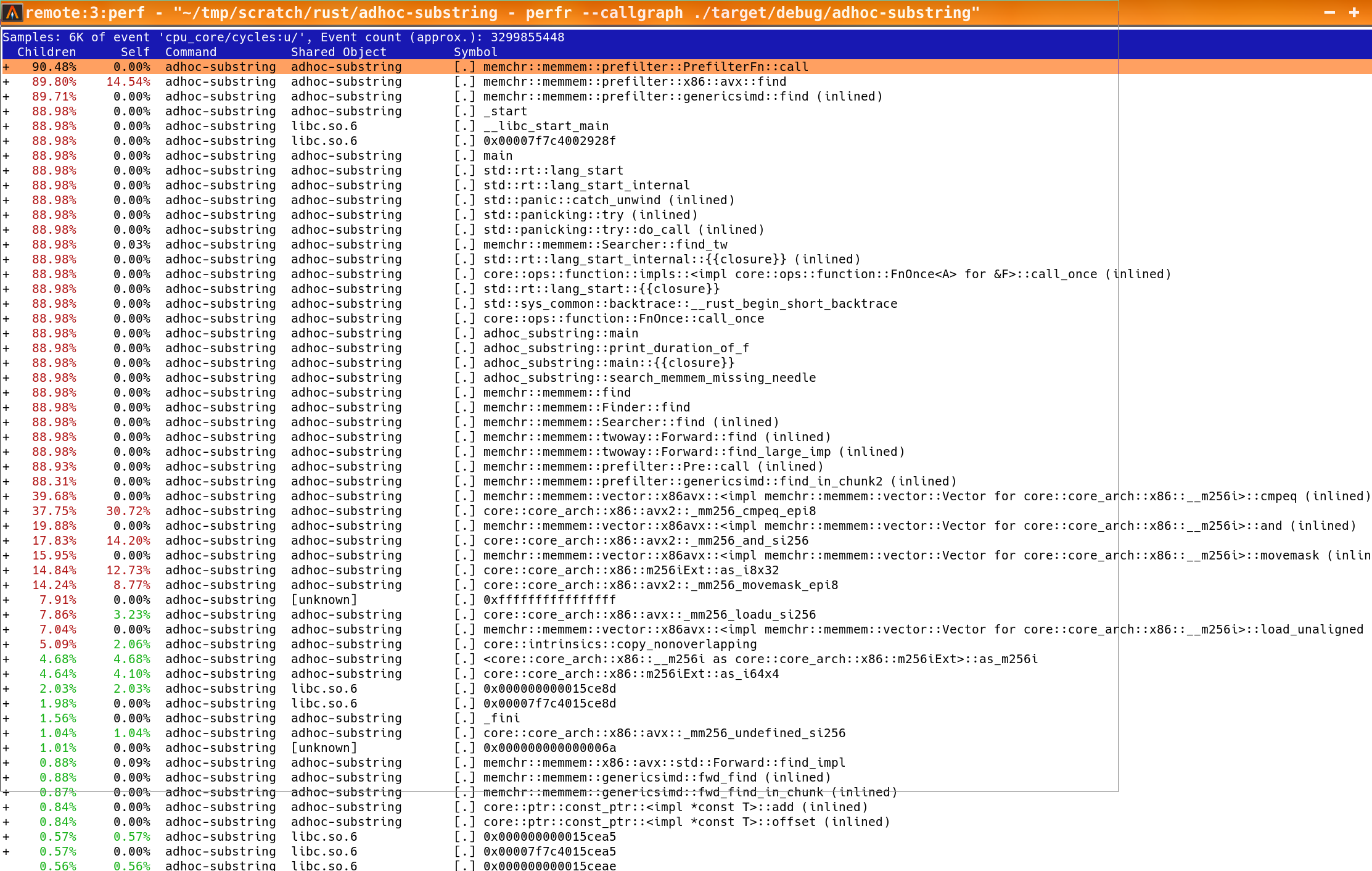
In the case of memmem, I would guess not. In debug builds, functions don't tend to get inlined. And the SIMD implementations quite literally live and die by function inlining. Running a profile confirms this:
You can see those low level SIMD intrinsics not getting inlined, and that's where most of the time is being spent. Which makes sense, because those are in the critical path.
Oh dear, that is bad... I had been assuming I could move to the portable SIMD API once that's stabilized, but if arm doesn't have movemask, then does that mean the portable API doesn't either? ... Well, okay, I spent ten minutes looking at std::simd and I can't answer in the affirmative or the negative as to whether there is a portable movemask operation. The docs are really hard to browse. My next step would be to go look at libc implementations and see how they implement memchr on arm platforms. The standard memchr implementation also uses movemask.
Popping up a level though, I don't think this is a blocker? We could just have the acceleration for x86.
Popping up another level, how are you solving the problem of "use SIMD in core" in the first place?
Yeah happy to have an issue on memchr about this. This issue might be a good place actually?
Ah, I missed they were specifically asking about your crate, rather than their own. Yeah, I assume SIMD intrinsics are semantically equivalent to unchecked access already.
Yes, they are unchecked in both debug and release mode, because all those checks are elided explicitly.
The point I was kind of hinting at here is that my experience is that unelided bounds checks are not what slows down debug builds. It's un-inlined functions, because function inlining is what enables the various "zero cost abstractions" to melt away. Of course, I grant that unelided bounds checks can penalize you, it's just probably not the common/principle explanation for why debug builds are slow.